

Cuando estemos trabajando con Elasticsearch debemos de manejar los siguientes conceptos básicos:
Cluster
Es una colección de nodos en los cuales se almacenan los datos. El cluster proporciona capacidades de indexación federadas y capacidades de búsqueda a través de los diferentes documentos.
El cluster es identificado por un id, por defecto “elasticsearch”. Los nombres de los cluster varian por entorno.
Nodo
Un nodo es un servidor que es parte del cluster cuya misión es almacenar documentos y participar en las capacidades de indexación del cluster. Cada nodo es identificado mediante un Universally Unique IDentifier (UUID) que es generado aleatoriamente.
Los nodos se pueden configurar para ser añadidos a un cluster específico. Por defecto se añaden al cluster denominado “elasticsearch”.
En un cluster podremos tener tantos nodos como queramos. Si bien podríamos tener un cluster de un solo nodo.
Índice
Un índice es una colección de documentos que tienen características similares. Por ejemplo podríamos tener la colección de “clientes” para guardar información de los mismos, otra colección que fuese “productos” para guardar información de los productos que compran los clientes,…
El índice se debe de especificar en minúsculas y es al que haremos referencia cuando realicemos las operaciones de indexación, búsqueda, actualización o borrado.
Tipo
El tipo nos sirve para hacer una partición lógica del índice en diferentes tipos de documentos. Es un concepto que Elasticsearch va a retirar este concepto en las nuevas versiones.
Documento
Será la información básica que va a ser indexada. Si hemos creado una colección de “clientes”, cada documento será la información relativa a un cliente. Los documentos se expresan en formato JSON.
Cada documento será almacenado en un indice/tipo, y dentro de un índice/tipo podremos tener tantos documentos como queramos.
Un índice puede tener un máximo de 2.147.483.519 de documentos.
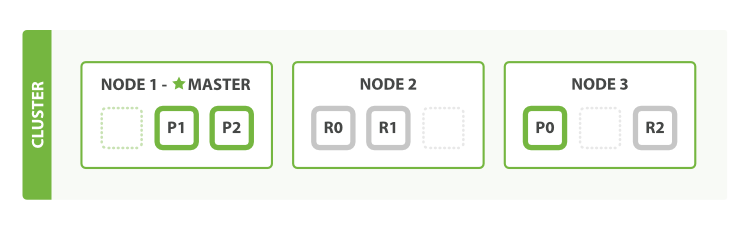
Sharding
Cuando almacenamos documentos dentro de un índice en un nodo podemos llegar a consumir toda la capacidad que tenemos de almacenamiento. Además almacenar muchos documentos dentro de un nodo puede llegar a sobrecargarlo.
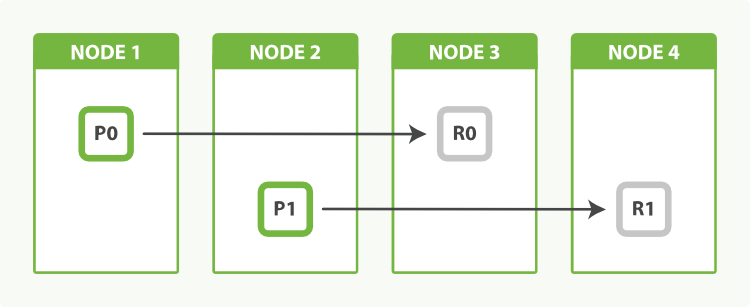
Es por ellos que en Elasticsearch podemos hacer una distribución del índice por diferentes nodos mediante técnicas de sharding. De esta manera, cuando creamos un índice podemos indicarle la cantidad de divisiones (o shards) en que queremos dividirlo.
Esta división de los índices por los diferentes nodos nos va a proporcionar dos cosas, por un lado la posibilidad de tener una escalabilidad horizontal y por otro el poder paralelizar consultas por los diferentes nodos.
La distribución del shard por los diferentes nodos se realiza de forma automática por Elasticsearch.
Réplicas
Al distribuir los índices por diferentes nodos dentro del cluster deberemos de tomar una serie de medidas por si alguno de los nodos falla. Es por eso que Elasticsearch nos ofrece la capacidad de realizar réplicas de los datos.
Las réplicas se realizar de los shards. Cuando hacemos una réplica esta nunca se almacenará en el mismo nodo que contiene la información original, proporcionandonos de esta forma la capacidad de recuperación ante fallos.
La definición de cuántos shards y réplicas queremos para un índice se hace en el momento de su creación.
Al realizar las réplicas contaremos con un shards primario y con shard de réplica, aunque, a posteriori, podremos cambiar el número de shards mediante los API _shrink y _split.
Con estos conceptos claros ya puedes ponerte a crear tu primer índice en Elasticsearch.